AI is changing software development, but not in the simplistic way most people describe.
The real shift is not only that AI can write code. The real shift is that AI can generate more code than teams can realistically review, understand, and govern with traditional workflows.
That creates a new bottleneck: software understanding.
For years, the industry optimized for speed. Faster development. Faster testing. Faster deployment. Faster iteration. AI accelerates that curve even further. Features move faster. Refactors happen faster. Pull requests multiply. Generated code enters repositories at a pace that manual review was never designed to absorb.
But the hard question remains: what does the software actually do?
That question is becoming unavoidable for engineering teams, security teams, auditors, compliance leaders, and executives responsible for complex software systems.
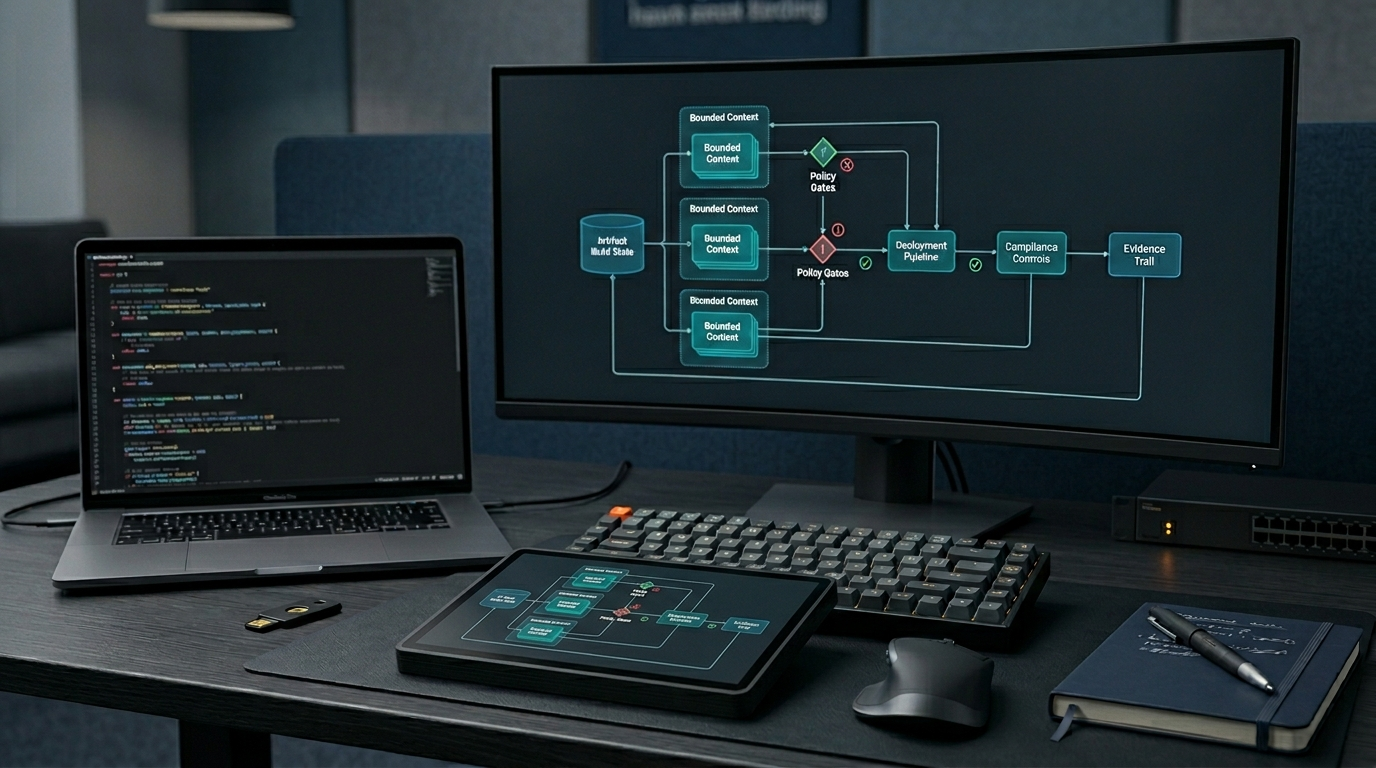
This is the category BRIK64 is building toward: Software Logic Evidence Infrastructure.
Software Logic Evidence Infrastructure is an evidence layer for repositories, AI-generated code, and software changes. It turns selected software logic into blueprints, logic diffs, gates, traceability records, declared scopes, and evidence packs that teams can inspect before trust is assumed.
In simple terms: it makes software logic reviewable, traceable, and reusable as evidence.
Why AI-generated code creates an evidence problem
AI coding tools are useful because they increase output. They help developers generate functions, refactor modules, scaffold applications, write tests, document APIs, and move faster through implementation work.
But more code does not automatically create more control.
AI-generated code can still introduce hidden assumptions, duplicated logic, fragile dependencies, inconsistent behavior, unreviewed edge cases, security weaknesses, compliance-relevant changes, architectural drift, and production risk.
The issue is not that AI-generated code is always bad. The issue is that generated code still needs accountable logic.
A reviewer still needs to understand what changed, why it changed, what risk it introduces, and whether it should move forward. Traditional software review was built around human-scale production. AI changes the volume equation. If code generation becomes abundant, review and evidence become the constraint.
This is why the next major software category will not only be about generating code. It will be about reviewing, explaining, and governing software logic.
What is Software Logic Evidence Infrastructure?
Software Logic Evidence Infrastructure is the technical layer that transforms selected software logic into structured evidence.
It sits close to the repository, the pull request, the CI/CD pipeline, and the engineering workflow. It does not replace developers, security teams, auditors, certification bodies, or legal counsel. It gives them better artifacts to work with.
A Software Logic Evidence Infrastructure platform should help answer practical questions:
- What logic exists inside this repository?
- What changed between versions?
- Which parts of the system are affected?
- Which logic was generated or modified by AI?
- Which rules were applied before promotion?
- Which gates passed or failed?
- What evidence was created?
- What is the declared scope of that evidence?
- What limitations remain?
Modern software teams do not only need more automation. They need evidence they can trust within explicit boundaries.
BRIK64 frames this category around six primitives: blueprints, logic diffs, gates, traceability records, evidence packs, and declared scope.
Together, these primitives create an evidence layer for software logic.
Blueprints make software logic reviewable
A blueprint is a structured representation of software logic.
It is not generic documentation. It is not a screenshot. It is not a loose architecture diagram that becomes outdated as soon as the repository changes.
A blueprint is designed to represent selected behavior in a way that can be reviewed, compared, governed, and reused.
Source code remains necessary. But raw source code is often too detailed, too noisy, or too implementation-specific for every stakeholder. A senior engineer may inspect the code directly. A security reviewer may need to understand risk-sensitive flows. A compliance team may need to know whether evidence exists for a controlled change. An executive may need confidence that the organization can explain critical software behavior.
A blueprint becomes the shared artifact between those layers.
The category phrase is simple: the blueprint is the reviewable architecture of software logic.
Logic diffs show meaning, not only text
Most development workflows already use code diffs. A code diff shows what changed in text.
But a text change is not always the same as a logic change.
A small modification can create a major behavior change. A large refactor can preserve behavior while changing structure. AI-generated patches can modify multiple files in ways that are difficult to evaluate quickly from raw diffs alone.
A logic diff focuses on meaning.
It should help teams understand what behavior changed, which rules changed, which flows changed, which modules are affected, which assumptions shifted, which areas require human review, and which changes may increase risk.
In AI-assisted development, this becomes critical. The reviewer does not only need to know that files changed. The reviewer needs to know what the change means.
Code diff shows text changes. Logic diff shows meaning changes.
Gates turn review policy into executable control
A gate is a control point that determines whether a software change can move forward under declared rules.
In traditional workflows, gates often appear as test suites, CI checks, approval rules, or security scans. Those are useful. Software Logic Evidence Infrastructure extends the concept toward logic-aware review.
A gate should state what rule was applied, what input was analyzed, what passed, what failed, why it failed, what evidence was produced, what scope was covered, and what limitations remain.
This matters because software governance cannot depend only on informal confidence.
If an AI-generated change touches authentication logic, payment behavior, medical data processing, financial calculations, safety-related controls, or any other critical path, teams need more than a green checkmark. They need to know what was checked, under what scope, and with what evidence.
Gates turn review policy into executable control.
Traceability records make decisions reconstructable
Software teams often need to reconstruct what happened after the fact.
What changed? Who approved it? What version was deployed? What evidence existed at the time? Which dependency was involved? Which gate passed? Which limitation was known?
A traceability record connects code, logic, version, change, decision, and evidence.
This is essential for software governance, security investigations, audit preparation, incident response, and regulated software workflows.
Without traceability, organizations are left with fragments: commits, tickets, logs, messages, dashboards, and institutional memory.
That is not enough for the AI era.
As systems become more automated and software generation becomes faster, traceability must become more structured.
Traceability turns software change into accountable history.
Evidence packs make review portable
An evidence pack is an exportable package of software evidence.
A useful evidence pack may include a repository reference, version, commit or artifact hash, blueprint, logic diff, gate results, dependency context, declared scope, known limitations, confidence boundaries, human-readable report, and machine-readable metadata.
The key idea is portability.
Evidence should not be trapped inside a pull request, a Slack thread, a meeting note, or someone's memory. It should be structured, reproducible, and exportable.
This is how software review becomes reusable across teams and processes.
Evidence packs make software review portable.
Declared scope is the boundary of trust
Declared scope is one of the most important principles behind BRIK64.
Every meaningful evidence claim needs a boundary.
What repository was analyzed? Which module? Which language? Which version? Which rules? Which gates? Which assumptions? Which limitations? Which areas were not covered?
This is where BRIK64 differs from vague claims about automated trust.
BRIK64 does not claim every code path is automatically correct. It does not claim software is magically safe. It does not replace auditors, safety engineers, certification bodies, or legal counsel.
Instead, BRIK64 is designed to produce structured software logic evidence under declared scope.
In serious software environments, trust is not created by confidence. It is created by evidence, boundaries, and reproducibility.
No scope, no claim. No evidence, no trust.
Why this matters to enterprises
The enterprise buyer will not buy AI forever. The enterprise buyer will buy risk reduction.
That means evidence, traceability, audit readiness, governance, security visibility, supplier control, operational resilience, and defensible software processes.
At the same time, technical buyers will not buy generic compliance language. Developers and security engineers need practical answers: what does this code do, what changed, what risk entered the system, what should be reviewed, what should be blocked, and what evidence exists?
This creates a market intersection between devtools, software supply chain security, GRC, assurance, and certification workflows.
That is where Software Logic Evidence Infrastructure belongs.
It is technical enough to live in the repository. It is structured enough to support security and governance. It is evidence-oriented enough to support audit readiness. And it is scope-bound enough to be credible in regulated environments.
How it differs from existing tool categories
Software Logic Evidence Infrastructure does not replace existing software tools. It connects to them and fills a gap between them.
Static analysis tools detect patterns, vulnerabilities, or quality issues. Testing frameworks validate selected behavior under selected conditions. SBOM tools list software components and dependencies. GRC platforms manage controls, policies, and audit workflows. AI coding tools generate code. Software supply chain tools track provenance, packages, vulnerabilities, and artifacts.
All of those categories matter.
But none of them fully owns the question: what evidence exists about the logic of the software and the meaning of its changes?
That is the gap BRIK64 is addressing.
Static analysis detects issues. Tests validate selected behavior. SBOMs describe ingredients. GRC manages controls. AI coding tools generate code. Software supply chain tools track components. BRIK64 focuses on software logic evidence.
The initial wedge: AI-generated code review
The first practical wedge for BRIK64 is AI-generated code review and logic evidence for repositories.
This is where the pain is immediate.
Developers are already using AI. Teams are already accepting generated changes. Code review is already under pressure. Security teams are already trying to understand the risk. Organizations are already asking how to control the process.
BRIK64 should start close to the developer workflow: CLI, repository analysis, blueprint generation, logic diff, gates, evidence pack export, CI/CD integration, and pull request evidence.
The first job-to-be-done is clear: understand what this code does, what changed, and whether it should move forward under the team's declared rules.
From there, the product can expand into team workflows, enterprise evidence registries, audit-ready reporting, and certification-ready evidence under declared scope.
Why regulated and critical software will feel this first
Regulated and critical industries will feel this pressure most intensely.
In finance, healthcare, energy, transportation, aerospace, automotive, defense, and industrial systems, software is not just an internal productivity layer. Software is operational risk.
A software change can affect safety, security, financial exposure, customer rights, infrastructure resilience, or legal responsibility.
In those environments, teams need more than velocity. They need evidence.
They need to demonstrate what changed, what was reviewed, what controls were applied, and what limitations were known.
This does not mean BRIK64 should claim to certify all critical software. That would be the wrong claim.
The defensible claim is more precise: BRIK64 helps produce structured, reproducible, and traceable software logic evidence that can support review, governance, audit readiness, and certification workflows under declared scope.
The future of software trust is evidence-based
Software trust is changing.
In the past, teams could often rely on confidence: experienced developers, familiar codebases, manual review, internal knowledge, and test suites.
Those things still matter. But they are no longer sufficient by themselves.
AI-generated code increases the volume of software. Regulation increases the demand for proof. Security increases the need for traceability. Complex systems increase the cost of misunderstanding. Enterprise governance increases the value of reusable evidence.
The next decade of software will require a new layer.
A layer that makes logic visible. A layer that makes changes explainable. A layer that makes gates executable. A layer that makes evidence portable. A layer that makes claims scope-bound.
That layer is Software Logic Evidence Infrastructure.
BRIK64 is building it because AI makes code cheap, but accountable software still needs evidence.